In a new series of blogs we give you insight about software engineering, as seen through the eyes of our technology team. Here our head of engineering, Gareth Davis, explores how to quantify bumps in the process.
In a technology organisation there is typically more work than can be accomplished in the short term. Delaying any of these pieces of work will entail a cost.
Some of this cost is easily measurable: "If we don't deliver this feature by 31/03 we owe the client x according to our contract." Some of this cost is imperceptible, intangible: "If we can't continuously deliver our software by the end of this year, our speed to market may no longer be competitive." One is measured by money, one could be measured by money if we guessed. Which feels more real? The answer is they are both real. One is predictable and the other is not. Different types of work have different costs of delay.
In everyday engineering it’s often difficult to classify work. The majority of the work that an engineering team completes doesn’t directly or visibly add value to products. Examples include automation of testing, deployment and release activities to remove manual duplication of effort. Maintaining supported versions of underlying dependencies keeps our products secure and stable. The value added for the end-user is not always obvious.
Some of this work is clear improvement and some of it is about protecting existing capabilities. There’s a grey area between these classifications.
The cost of improvement delay is intangible in the present. In the future it becomes increasingly real and expensive.
Each type of work also has a different cost of being delayed in favour of something else.
This post aims to provide clarification about what is and is not improvement work and the possible cost of delaying that work. The cost of improvement delay is intangible in the present. In the future it becomes increasingly real and expensive.
What is improvement work?
The best-available definition of improvement work that I could find is:
“Work that results in faster or increasingly efficient delivery of value.”
This includes work that makes it easier for engineers to:
- Release our software
- Build our software
- Support our software
- Change or extend our software
What is not improvement work?
A lot of work that isn’t a bug fix or a new feature for our software can be innately technical. It is a natural reaction when faced with complexity, which requires understanding in order to determine value, to resist the effort required to achieve that understanding. As a result of this there is a tendency to categorise all technical work as improvement work. This is simply not a correct result. As is common in life, there’s no clear cut definition of improvement work and there’s a grey area in the middle. A lot of technical work actually adds value to our products or protects existing value.
This includes work that:
- Keeps our software supportable or its dependencies (software libraries or platforms) supported
- Maintains the current build, deployment and release of our software
- Compliant with current non-functional standards such as accessibility, performance, resiliency or security (there are other ‘ilities’)
| Clearly Improvement | The Grey Area ™ | Clearly Value |
|---|---|---|
| Speed, efficiency, ease of delivery | ??? | Non-functional requirements, standards, supported, maintenance of software and capabilities. |
Costs of delay
Cost of delay is 'a way of communicating the impact of time on the outcomes we hope to achieve.' More formally, it is 'the partial derivative of the total expected value with respect to time.' Cost of delay combines an understanding of value with how that value leaks away over time. (Wikipedia).
It is no surprise given this definition that different types of work have different costs of delay. There are four main cost types which align with four broad categories of work. Each is explained below to illustrate the delay cost over time, some examples of the types of work these apply to and a relative indication of short and long term costs (Essential Kanban Condensed).
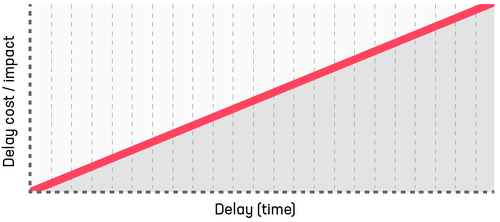
Expedite work: high short-term expense, huge longer-term costs
Expedite work is typically very high urgency and there's no point in the future where the cost decreases - it just goes on increasing. Expedite work could include situations like a live incident requiring configuration or code change to restore service, or a newly-discovered design or build issue which is blocking us or a client from delivering or obtaining value.
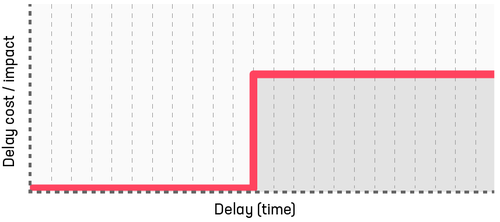
Fixed date work: no short-term expense, moderate longer-term costs
Fixed date work is the most predictable in that there is typically no cost until a one-off impact on the date. At the point the cost is incurred, it typically doesn't increase. Fixed date work could include a contracted client delivery with a fixed date or a live incident with an associated SLA.
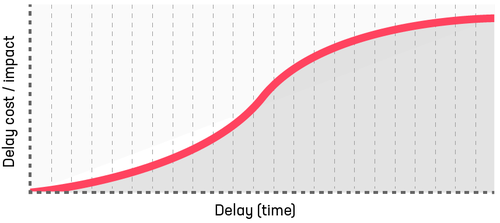
Standard work: lower short-term expense, moderate longer-term costs
Standard work is typical, has 'regular' urgency and no fixed date or penalty. The increasing cost of delay may tail off as value is lost and tends towards a total cost over time. Standard work could include new features on the product roadmap, enhancements to existing software that improves the user experience or productivity or a non-critical bug with no fixed SLA.
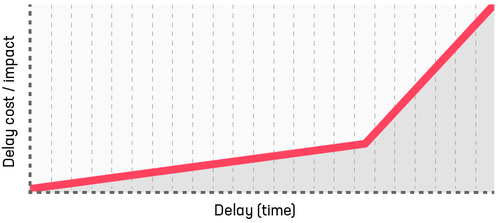
Intangible work: lower short-term expense, moderate to high longer-term costs
Intangible work is the most difficult to conceptualise (hence the appropriate name). This work is typically perceived as low urgency in the short-term. Longer-term, as time passes, this may be followed by high urgency. Examples include improving practices to keep us competitive in the marketplace, repaying technical debt and adopting new technologies and tools.
Interactions over time
In the long term costs of delay can transition from one to another:
Standard cost of delay can change to fixed date cost of delay as the increasing loss of value tends towards 0 (a fixed total cost)
Intangible work can change to become expedite work in the long term.
What can we do with this?
When we're planning work and weighing up the cost of delaying different pieces of work we should be aiming to quantify the cost of delaying each piece of work and over what time frame. This should give us a better indicator of the value we're sacrificing by prioritising one piece of work over another. This applies to everything we do: product features, technical improvement, supporting clients and organisational change to support the previous three. There are many models available, one being 'Weighted Shortest Job First' from SAFE (I'm by no means a SAFE advocate. This is just an example).
If we look at how technology companies deliver to clients, it’s critical to quantify the cost of delay as early as possible. Each organisation will have it’s own way of doing this - we use our own Iress Delivery Framework. The framework includes user research and discovery workshops to define the software we build followed by measurement and learning as feedback loops.
Value is relative against other factors, not least of which is cost. The earlier the cost of delaying a piece of work can be understood, the earlier its true value can be determined.
This blog post was written by:
Gareth Davis - Head of engineering at Iress
Follow him on: LinkedIn
